In the post Convert HTML to PDF in Java Using Flying Saucer, OpenPDF we saw one way to convert HTML to PDF, in this tutorial you’ll see how to convert HTML to PDF in Java using Openhtmltopdf, PDFBox and jsoup.
To know more about PDFBox check this post- Generating PDF in Java Using PDFBox Tutorial
Convert HTML to PDF using Openhtmltopdf – How it works
Open HTML to PDF is a pure-Java library for rendering arbitrary well-formed XML/XHTML (and even HTML5) using CSS 2.1 for layout and formatting, outputting to PDF or images. Steps for HTML to PDF conversion are as follows-
- First step is to ensure that you have a well formed HTML that is done using jsoup which takes the HTML as input and parse it to return a well formed HTML.
- Openhtmltopdf generates a rendered representation of the XHTML using CSS for layout and formatting.
- PDFBox is used to generate PDF document from that rendered representation.
Maven Dependencies
Apache Maven dependencies for Openhtmltopdf, jsoup and PDFBox are as given below-
<dependency> <!-- ALWAYS required --> <groupId>com.openhtmltopdf</groupId> <artifactId>openhtmltopdf-core</artifactId> <version>${openhtml.version}</version> </dependency> <dependency> <!-- Required for PDF output. --> <groupId>com.openhtmltopdf</groupId> <artifactId>openhtmltopdf-pdfbox</artifactId> <version>${openhtml.version}</version> </dependency> <!-- jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.13.1</version> </dependency>
Add this in property section of the POM
<properties> <openhtml.version>1.0.4</openhtml.version> </properties>
Convert HTML to PDF using Openhtmltopdf and PDFBox Java Program
While converting HTML to PDF Java program tries to address the three common problems-
- How to display image in PDF which is given there in HTML using <img src="" ..> tag.
- How to add any specific web font.
- How to ensure that external CSS used in HTML is also used to style the generated PDF.
Folder Structure used for the example program is as given here. Within PDFBox folder we have the HTML file, a true type font file and png image file and PDFBox/css folder has the css file.
- PDFBox MyPage.html Gabriola.ttf image.png --css mystyles.cssMyPage.html
This is the HTML which we have to convert to PDF.
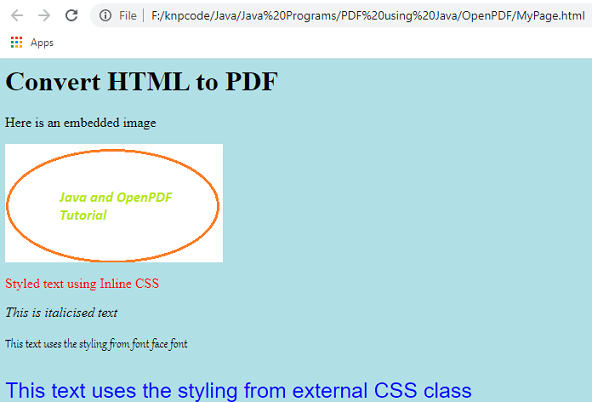
<html lang="en"> <head> <title>MyPage</title> <style type="text/css"> body{background-color: powderblue;} </style> <link href="css/mystyles.css" rel="stylesheet" > </head> <body> <h1>Convert HTML to PDF</h1> <p>Here is an embedded image</p> <img src="image.png" width="250" height="150"> <p style="color:red">Styled text using Inline CSS</p> <i>This is italicised text</i> <p class="fontclass">This text uses the styling from font face font</p> <p class="myclass">This text uses the styling from external CSS class</p> </body> </html>
As you can see this HTML used inline CSS with <p> tag
<p style="color:red">Styled text using Inline CSS</p>
Uses internal CSS with in the <style></style> tag and also uses an external CSS. All these stylings should be reflected in the PDF too.
There is also an image with the relative path.
mystyles.cssIn the css @font-face rule is used to specify a font and the URL where it can be found.
Using @page rule CSS properties are specified to be used when printing a document.
@font-face { font-family: myFont; src: url("../Gabriola.ttf"); } .fontclass{ font-family: myFont; } @Page { size: 8.5in 11in; margin: 1in; } .myclass{ font-family: Helvetica, sans-serif; font-size:25; font-weight: normal; color: blue; }
That’s how HTML is rendered in the Chrome browser.
import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; import java.nio.file.FileSystems; import org.jsoup.Jsoup; import org.jsoup.helper.W3CDom; import org.w3c.dom.Document; import com.openhtmltopdf.pdfboxout.PdfRendererBuilder; public class HtmlToPdf { public static void main(String[] args) { try { // Source HTML file String inputHTML = "F:\\knpcode\\Java\\Java Programs\\PDF using Java\\PDFBox\\MyPage.html"; // Generated PDF file name String outputPdf = "F:\\knpcode\\Java\\Java Programs\\PDF using Java\\PDFBox\\Output.pdf"; htmlToPdf(inputHTML, outputPdf); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } private static Document html5ParseDocument(String inputHTML) throws IOException{ org.jsoup.nodes.Document doc; System.out.println("parsing ..."); doc = Jsoup.parse(new File(inputHTML), "UTF-8"); System.out.println("parsing done ..." + doc); return new W3CDom().fromJsoup(doc); } private static void htmlToPdf(String inputHTML, String outputPdf) throws IOException { Document doc = html5ParseDocument(inputHTML); String baseUri = FileSystems.getDefault() .getPath("F:/", "knpcode/Java/", "Java Programs/PDF using Java/PDFBox/") .toUri() .toString(); OutputStream os = new FileOutputStream(outputPdf); PdfRendererBuilder builder = new PdfRendererBuilder(); builder.withUri(outputPdf); builder.toStream(os); // using absolute path here builder.useFont(new File("F:\\knpcode\\Java\\Java Programs\\PDF using Java\\PDFBox\\Gabriola.ttf"), "Gabriola"); builder.withW3cDocument(doc, baseUri); //builder.useUriResolver(new MyResolver()); builder.run(); System.out.println("PDF generation completed"); os.close(); } }
In the program some important points to note are-
- In the method html5ParseDocument jsoup.parse() method is used to generate a well formed HTML.
- Then that well formed HTML is used to generate the PDF using the HTML as input.
- You can see that a BaseUri is created which is then passed in the method builder.withW3cDocument(doc, baseUri); that way program knows how to resolve the relative paths against this bseUri.
- using useFont method one font is also added by passing the absolute path to the location where the font file is downloaded.

You can also plugin your own custom resolver which can be used to resolve relative URIs, URIs in a private address space or even reject a URI. Your custom resolver needs to implement FSUriResolver interface.
import java.net.URI; import java.net.URISyntaxException; import com.openhtmltopdf.extend.FSUriResolver; import com.openhtmltopdf.swing.NaiveUserAgent; public class MyResolver implements FSUriResolver { final NaiveUserAgent.DefaultUriResolver defaultUriResolver = new NaiveUserAgent.DefaultUriResolver(); @Override public String resolveURI(String baseUri, String uri) { System.out.println("URI--- " + uri); String supResolved = defaultUriResolver.resolveURI(baseUri, uri); if (supResolved == null || supResolved.isEmpty()) return null; try { URI uriObj = new URI(supResolved); //System.out.println("resolveURI..." + uriObj.toString()); return uriObj.toString(); }catch (URISyntaxException e) { e.printStackTrace(); } return null; } }
You can use this custom resolver by setting it like this-
builder.useUriResolver(new MyResolver());
That's all for the topic Convert HTML to PDF in Java Using Openhtmltopdf, PDFBox. If something is missing or you have something to share about the topic please write a comment.
You may also like
- Password Protected PDF Using PDFBox in Java
- Generate PDF From XML in Java Using Apache FOP
- GZIP File in Java – Compression And Decompression
- Display Time in 12 Hour Format With AM/PM in Java
- Java Condition Interface
- JDBC DatabaseMetaData Interface
- Data Compression in Hadoop Framework
- Advantages and Disadvantages of Autowiring in Spring
No comments:
Post a Comment