HDFS (Hadoop Distributed File System) is a distributed file system, that is part of Hadoop framework. HDFS in Hadoop framework is designed to store and manage very large files. In HDFS large file is divided into blocks and then those blocks are distributed across the nodes of the cluster.
When file is stored across nodes in a distributed way there must be a provision for eventualities like-
- what if a node goes bad?
- what if a block gets corrupted?
HDFS is designed to run on commodity hardware because of that also chances of node going bad is high.
HDFS, apart from storing large files, manages all these situations and provides a reliable, fault tolerant file system.
Block size in HDFS
In any file system read and write happens for a block which is the amount of data that can be read or written at a time. As Example block size for windows is 4 KB. Since HDFS in Hadoop framework is designed for storing large files so the block size in HDFS is also quite large, 128 MB by default in Hadoop 2.x versions, it was 64 MB in Hadoop 1.x versions.
For example– If you put a 256 MB file in a HDFS where block size is 128 MB then that file will be divided into two chunks of 128 MB each. These two chunks will be distributed across nodes in the cluster.
Here note that in HDFS whole block is not used if file is smaller than 128 MB. As example if file is 60 MB in size then only 60 MB will be used on the disk to store that file not the whole 128 MB disk block. In Windows even if a file is smaller then 4 KB it will take that much block size on the disk. You can check by seeing the file properties where you will have two attributes size and File size on disk.
How large block size helps in HDFS
- Namenode metadata– For every file, metadata information like blocks of the file and where that block is stored is tracked by Namenode. On top of that Namenode keeps that metadata information in RAM for easy access. Thus having smaller blocks will mean more block information to be tracked by Namenode resulting in slowing it down.
- Map tasks– When you run a MapReduce program, for each input split (Which is equal to block) a map task is created. Having smaller blocks will result in creation of more Map tasks having much less data to process.
- Low latency Vs high throughput- HDFS is designed more for batch processing rather than interactive use by users. The emphasis is on high throughput of data access rather than low latency of data access. If block size is small you may get benefits like less time to send it to node across network, once you start reading the block time taken to get to the first record will again be less because of the smaller block size but at the same time data processed with in a block will be less. So smaller block size will mean storing and reaching to the data will take less time but processing will take more time which goes against the design of HDFS.
HDFS block replication in Hadoop
In a multi-node cluster (cluster running to even thousands of nodes) there is a high possibility of one of these happening-
- Node stops working.
- Network connection to the node stops working.
- Block of a file stored on a node gets corrupted.
As a remedy for these scenarios, HDFS provides redundancy. Each block is replicated thrice by default which means once the file is divided into blocks each block is stored in three different Datanodes. In case one of the Datanodes stops responding there is a redundant block available in another Datanode that can be used.
As Example– There are two files logs.txt and clicks.txt which are stored in a cluster having 5 nodes. When these files are put in HDFS both of these files are divided into two blocks each.
logs.txt– block-1, block-2
clicks.txt– block-3, block-4
Then with the default replication factor of 3 block distribution across 5 nodes may look like the given image
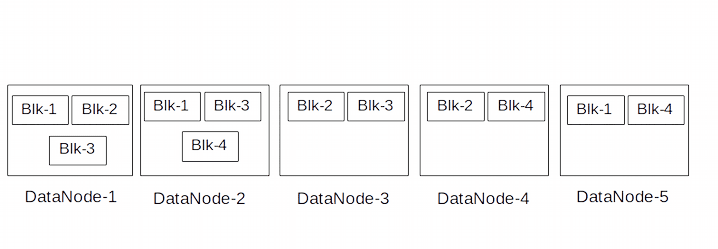
Refer HDFS Replica Placement Policy to know more about replica placement in Hadoop.
Configuring HDFS default block size and replication factor
If you want to change the default block size of 128 MB or the default replication factor of 3 you will have to edit the /etc/hadoop/hdfs-site.xml in your hadoop installation directory.
For changing block size add/edit the following tag, block size is given in bits here– 128 MB = 128 * 1024 * 1024 = 13417728
<property> <name>dfs.block.size<name> <value>134217728<value> <description>Block size<description> </property>For changing replication factor add/edit the following tag -
<property> <name>dfs.replication</name> <value>3</value> </property>
Namenode and Datanode
HDFS has a master/slave architecture which consists of a Namenode (master) and a number of Datanodes (slaves or workers).
Namenode manages the file system namespace and regulates access to files by clients. Namenode also determines the mapping of blocks to DataNodes.
DataNodes manage storage attached to the nodes that they run on, they store the blocks of the files. Datanodes are also responsible for serving read and write requests from the file system’s clients.
Refer NameNode, Secondary Namenode and Datanode in HDFS to know about NameNode, DataNode and Secondary Namenode in Hadoop.
Points to remember
- HDFS is designed to work with applications that process large data sets, where the philosophy is write-once, read-many-times. That is why arbitrary updates are not permitted though you can append/truncate a file.
- Files put in HDFS are split into blocks. Default block size is 128 MB in Hadoop 2.x versions.
- Each block is replicated across nodes. Default replication factor is 3.
- For files that are copied in HDFS, file metadata is stored in Namenode.
- File blocks are stored on Datanodes.
That's all for the topic Introduction to Hadoop Distributed File System (HDFS). If something is missing or you have something to share about the topic please write a comment.
You may also like
- How to Fix Corrupt Blocks And Under Replicated Blocks in HDFS
- Java Program to Read a File From HDFS
- Avro MapReduce Example
- Introduction to YARN in Hadoop
- Java Operators: Assignment, Arithmetic And Unary
- How to Convert File to Byte Array in Java
- Constructor Dependency Injection in Spring
- Abstraction in Python With Examples
No comments:
Post a Comment