In this post we’ll see the HDFS data flow in Hadoop. What happens internally when file is read in HDFS and what happens internally when file is written in HDFS.
Consulting the configuration
While reading or writing a file in HDFS first thing Hadoop framework does is to consult the configuration files (core-site.xml and core-default.xml) to get the FileSystem used. Property looked for is fs.defaultFS which has URI as a value (hdfs://hostname:port). With in the URI scheme is there which in this case will be HDFS.
Another property it has to look for is in the form fs.SCHEME.impl which names the FileSystem implementation
class. Since scheme is HDFS so the configuration property looked for is fs.hdfs.impl and the value is
DistributedFileSystem (implementation class). Note that in recent releases this property fs.hdfs.impl is getting replaced
by fs.AbstractFileSystem.hdfs.impl and the value is Hdfs. So instead of org.apache.hadoop.hdfs.DistributedFileSystem.java
the implementation class for HDFS file system by default will be org.apache.hadoop.fs.Hdfs.java. In this post we’ll take
DistributedFileSystem class as the implementation class for the HDFS scheme.
Getting instance of DFSClient
Once implementing class is determined i.e. DistributedFileSystem.java and initialized, this class
DistributedFileSystem in turn will create an instance of DFSClient.
DFSClient can connect to a Hadoop Filesystem and perform basic file tasks. DFSClient reads configuration related to HDFS which includes configuration for block size (dfs.blocksize) and block replication factor (dfs.replication).
Till this stage process is common whether you are reading a file from HDFS or writing a file to HDFS. Now let’s see what all happens when a file is written to HDFS.
Writing file to HDFS - Internal steps
Once a request for writing a file to HDFS comes through any client application, after performing the above mentioned steps, where DistributedFileSystem class is initialized and instance of DFSClient created, create() method of the DistributedFileSystem will be called.
Refer Java Program to Write a File in HDFS to see how to use Hadoop Java API to write a file in HDFS.
DistributedFileSystem also connects to the Namenode to intimate it about creating metadata about new file. Namenode performs various checks related to new file. If verification fails then file creation doesn’t happen and the IOException is thrown back to the client.
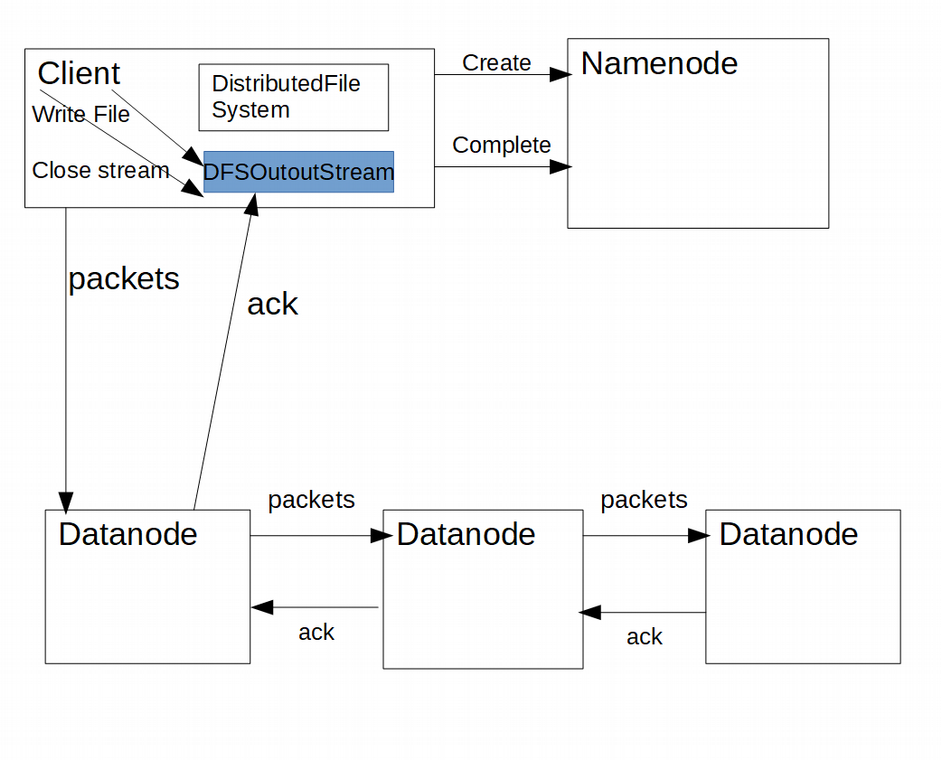
If verification passes then the Namenode will store the metadata about the file. From create() method of DistributedFileSystem, create() method of the DFSClient will be called in turn which returns DFSOutputStream through which data is streamed.
As the client writes data it is cached internally by DFSOutputStream. Data is also broken up into packets where each packet is typically 64K in size. These packets are enqueued into dataQueue.
There is another class DataStreamer which is responsible for sending these data packets to the Datanodes in the pipeline. DataStreamer class retrieves the list of Datanodes having the block locations, where file blocks have to be written, from the Namenode. If we take the default replication factor of 3 there will be three Datanodes in the pipeline.
The DataStreamer thread picks up packets from the dataQueue, sends it to the first datanode in the pipeline which stores it and that Datanode forwards those packets to the second Datanode which stores them and forwards the packet to the third Datanode in the pipeline.
Apart from dataQueue, DFSOutputStream also maintains another queue called ackQueue. When DataStreamer thread sends packets to the first Datanode in the pipeline it moves the packet from the dataQueue to the ackQueue. Only when a successful acknowledgement for a packet is received from all Datanodes in a pipeline, the corresponding packet is removed from the ackQueue. Note that acknowledgement from Datanodes are also pipelined in the reverse order.
When each DataNode in the pipeline has completed writing the block locally, DataNode also notify the NameNode of their block storage.
In case of any error, like Datanode where block is being written failing, the pipeline is closed and all outstanding packets are moved from ackQueue and added to the front of dataQueue. A new pipeline is setup by eliminating the bad datanode from the original pipeline. The DataStreamer now starts sending packets from the dataQueue.
When all the file data is written to the stream, client calls close() on the stream. Before closing the stream remaining packets in the queue are flushed to the Datanodes and acknowledgement received. Then only the Namenode is notified to signal the completion.
Following image represents the HDFS data flow in case of file write in HDFS.
Reading File from HDFS - Internal steps
Now let’s see the internal flow of file read in HDFS.
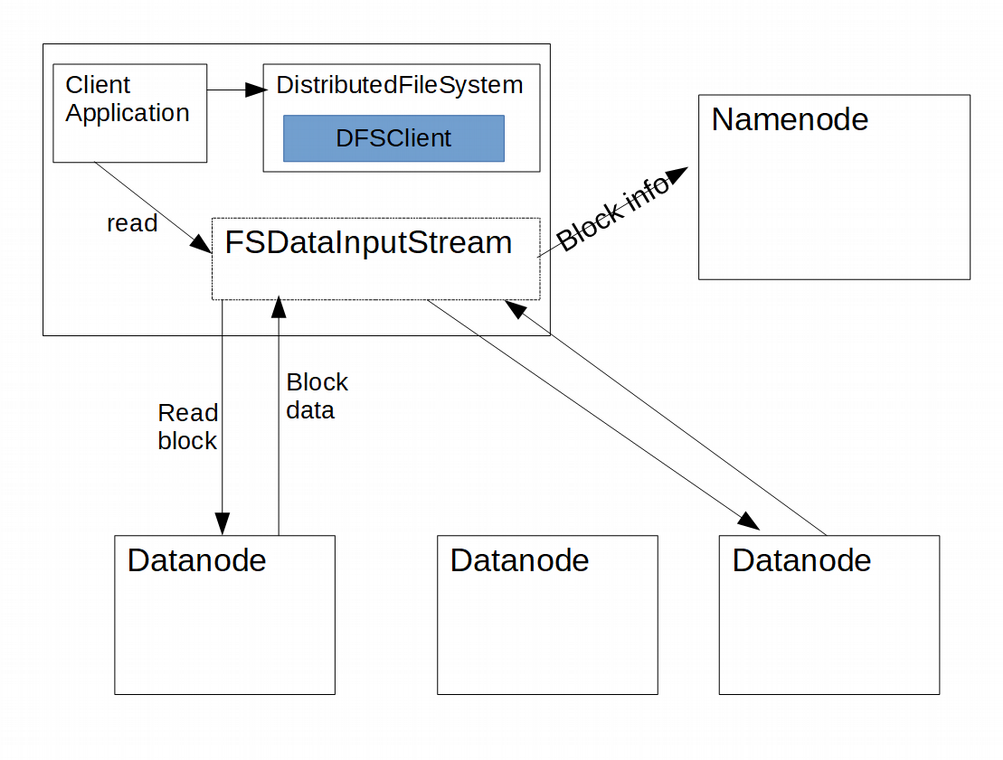
Once a request for reading a file from HDFS comes through any client application, after performing the above mentioned common steps, where DistributedFileSystem class is initialized and instance of DFSClient created, open() method of the DistributedFileSystem will be called which in turn calls the open() method on DFSClient and there instance of DFSInputStream is created.
Refer Java Program to Read a File From HDFS to see how to use Hadoop Java API to read a file in HDFS.
DFSInputStream connects to Namenode to get the list of Datanodes having blocks of the file for first few blocks of the file. In the list that Namenode returns, Datanodes are also sorted by their proximity to the client. If client application happens to run on the same Datanode where file block is also stored then that Datanode is preferred over any remote node.
- Refer HDFS Replica Placement Policy to know more about how block replicas are placed.
Then client calls read() on the stream, DFSInputStream which already has a list of Datanodes, connects to the Datanode which has the first block of the file and keep streaming the block until the end of block is reached. Then connection to that Datanode is closed and same process is repeated with the Datanode having the next block.
Parallely DFSInputStream will also communicate with the Namenode to get the datanode locations for more blocks of the file if needed.
When all the blocks of the file are read the client calls close() on the FSDataInputStream.
In case of any error while reading block data from the Datanode, DFSINputStream connects to the next closest Datanode for that block. Note that every block is stored in three Datanodes if we take the default replication factor of three.
Following image represents the HDFS data flow in case of file read in HDFS.
That's all for the topic HDFS Data Flow - File Read And Write in HDFS. If something is missing or you have something to share about the topic please write a comment.
You may also like
No comments:
Post a Comment