This post shows what is HDFS federation in Hadoop framework and what configuration changes are required for setting up HDFS federation.
Problem with HDFS architecture
In a Hadoop cluster namespace management and block management both are done by Namenode. So, essentially the Namenode has to perform the following tasks-
1- Namespace management-
- Keep file metadata.
- Support all the namespace related file system operations such as create, delete, modify and list files and directories.
2- Block management-
- Managing Datanodes in a cluster by handling registrations, and periodic heart beats.
- Processes block reports and maintains location of blocks.
- Supports block related operations such as create, delete, modify and get block location.
- Manages replica placement, block replication for under replicated blocks, and deletes blocks that are over replicated.
As the prior HDFS architecture allows only a single namespace for the entire cluster and a single Namenode manages the namespace, in a large cluster this architecture may pose problem in terms of Namenode scaling.
HDFS federation, introduced in the Hadoop 2.x release, addresses this limitation by adding support for multiple Namenodes/namespaces to HDFS.
Multiple Namenodes/Namespaces in HDFS Federation
HDFS federation uses multiple independent Namenodes where each Namenode manages a part of the namespace that helps to scale name service horizontally.
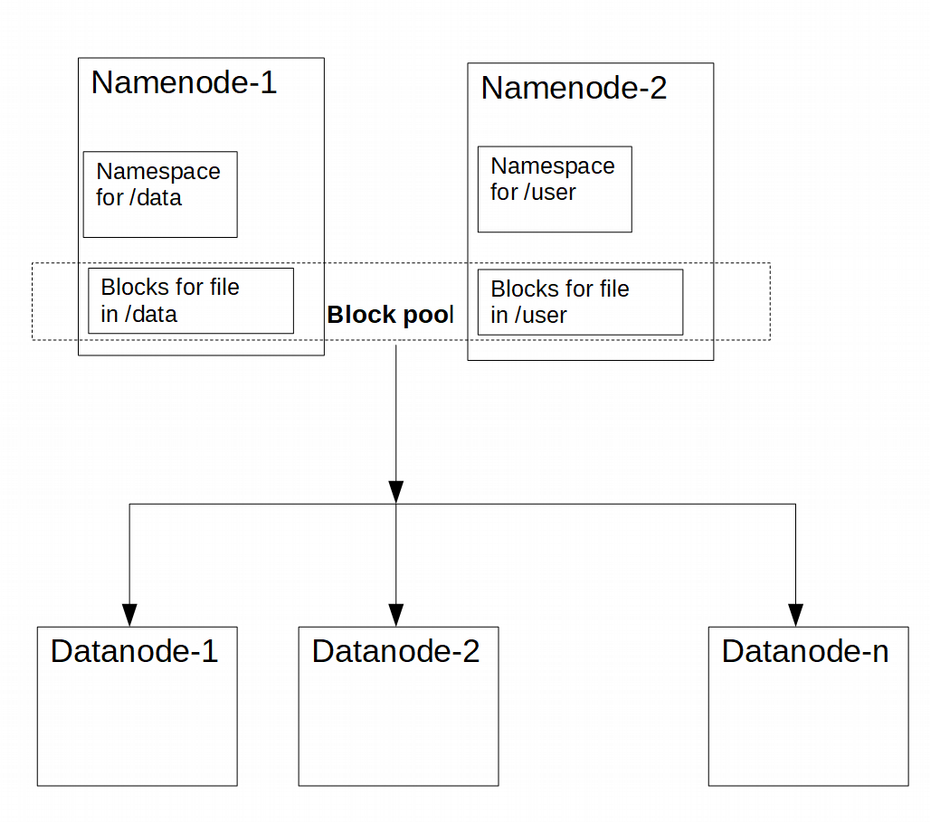
As example– Let’s say there are two namespace volumes /user and /data. Then under HDFS federation there can be two Namenodes, one Namenode managing the files under /user and another Namenode managing the files under /data.
These Namenodes are federated; the Namenodes are independent and do not require coordination with each other.
Namespace volume
In HDFS federation a Namenode manages a Namespace volume, where a Namespace volume consists of-
- 1- Metadata for the namespace managed by Namenode.
- 2- A block pool which has blocks for all the files stored in that namespace.
Datanodes still store blocks for all the block pools in the cluster so each Datanode registers with all the Namenodes in the cluster.
Each Block Pool is managed independently by a Namenode so there is no need for coordination with the other namespaces managed by other Namenodes.
Since there is no inter-communication among multiple Namenodes and Datanodes communicate with all the Namenodes the failure of one Namenode does not prevent the Datanode from serving other Namenodes in the cluster.
If we take our example of two namespace volumes /user and /data and two Namenodes managing these two namepsaces then following image shows the HDFS federation architecture for this-
Configuration Changes in Hadoop for HDFS federation
If you are using HDFS federation then client side mount tables are used to mount the name space volumes. Client applications will use these client side mount tables to do the mapping of file path to Namenode. For configuration of it ViewFs file system is used. In the configuration of each cluster, the default file system is set to the mount table for that cluster, that change is done in core-site.xml-
<property> <name>fs.defaultFS</name> <value>viewfs://clusterX</value> </property>
The authority following the viewfs:// scheme in the URI is the mount table name. It is recommended that the mount table of a cluster should be named by the cluster name. Then Hadoop system will look for a mount table with the name “clusterX” in the Hadoop configuration files.
Also in hdfs-site.xml you need to configure dfs.nameservices property which provides the logical name for this new nameservice. Configure this property with a list of comma separated NameServiceIDs. This will be used by the Datanodes to determine the Namenodes in the cluster. You can choose a logical name for this nameservice, as example mycluster1, mycluster2.
<property> <name>dfs.nameservices</name> <value>mycluster1, mycluster2</value> </property>
Then the configuration parameters for each Namenode and Secondary Namenode/BackupNode/Checkpointer are to be suffixed with the corresponding NameServiceID.
As example- Property dfs.namenode.http-address after suffixing with NameServiceID will become- dfs.namenode.http-address.mycluster1
Property dfs.namenode.secondary.http-address after suffixing with NameServiceID will become- dfs.namenode.secondary.http-address.mycluster2
That's all for the topic What is HDFS Federation in Hadoop. If something is missing or you have something to share about the topic please write a comment.
You may also like
No comments:
Post a Comment