In this post we'll see what is HDFS high availability, high availability architecture and the configuration needed for HDFS high availability in Hadoop cluster.
Some background on HDFS high availability
Prior to Hadoop 2, the NameNode was a single point of failure (SPOF) in an HDFS cluster. In a HDFS cluster there’s a single Namenode and if that machine or process went down the whole cluster would become unavailable until the Namenode was either restarted or brought up on a separate machine.
Having a Secondary Namenode would help in keeping the fsimage file merged with edit log thus reducing the start up time for Namenode and helped in data loss but it can’t take place of the Namenode quickly in case of Namenode failover. In short there was no provision for high availability of the file system.
This impacted the total availability of the HDFS cluster in the following ways-
- Any unplanned event such as a system crash would result in unavailability of the cluster until an operator restarted the Namenode.
- Any planned event such as software or hardware upgrades on the NameNode machine would result in periods of cluster downtime.
In any of these cases, unplanned or planned, administrator has to bring up a new system as namenode\Restart the Namenode which will stay in Safemode while-
- It loads the file system state into memory using fsimage and edit log.
- Gets enough block report from Datanodes.
That may take up to half an hour in a large cluster during which period Namenode won’t be able to serve requests.
The HDFS high availability tries to solve this problem by having two Namenodes in the same cluster in an active/passive configuration.
HDFS high availability architecture
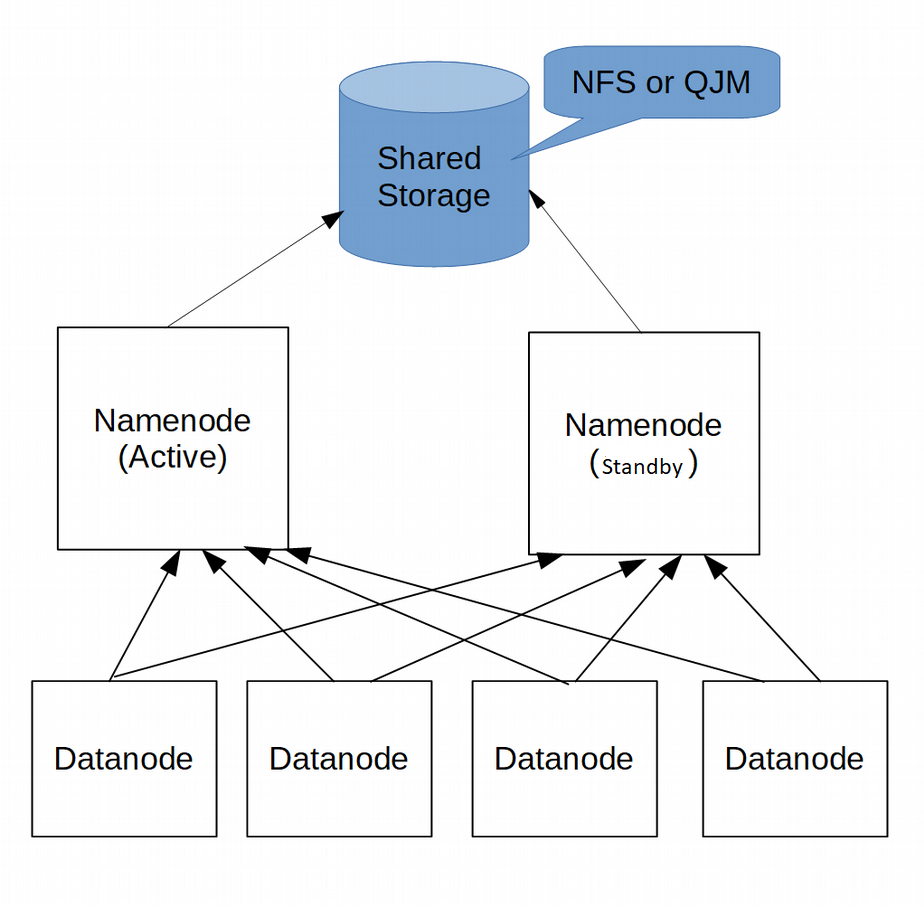
In HDFS HA cluster, two systems are configured as Namenode. At any given time, only one of the Namenode is active and serves the client requests where as other Namenode remains in standby state.
The Namenode which is in standby state doesn’t serve any client request, it just needs to keep it state synchronized with the active Namenode so that it can provide a fast failover if necessary.
For synchronizing the state between the two Namenodes, highly available shared storage is used. Both of the nodes communicate with this shared storage. When any namespace modification is performed by the Active node, it logs a record of the modification to edit log stored in that shared storage. The Standby node also communicate with the shared storage and applies the changes in edit log to its own namespace.
Both of the Namenodes should also have the location of all blocks in the Datanodes. Since that information is not persisted and kept in Namenode memory, Datanodes must send block location to both Namenodes. DataNodes are configured with the location of both NameNodes in order to do that.
In case of a failover, the Standby Namenode will ensure that it has read all of the edits from the shared storage before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before a failover occurs.
Types of shared storage used in HDFS HA
HDFS high availability can use shared NFS or Quorum Journal Manager as the shared storage that is used by both Namenodes.
In case of NFS it is required that both Namenode have access to a directory on a shared storage device where edit log changes can be written as well as read.
In case of QJM both Namenodes communicate with a group of separate daemons called “JournalNodes” (JNs). Any record of the namespace modification is logged to a majority of these Jns.
In a typical QJM implementation there are three journal nodes, so that it remains available even if one of the journal nodes become unavailable.
Namenode Failover
In case of active Namenode failover in HDFS high availability it has to be ensured that the standby Namenode becomes active whereas the previously active Namenode transitions to standby.
You can initiate a failover manually in HDFS HA using hdfs haadmin -failover subcommand.
This subcommand causes a failover from the first provided NameNode to the second. If the first NameNode is in the Standby state, this command simply transitions the second to the Active state without error. If the first NameNode is in the Active state, first an attempt will be made to gracefully transition it to the Standby state. If this fails, the fencing methods (as configured by dfs.ha.fencing.methods) will be attempted in order until one succeeds. Only after this process will the second NameNode be transitioned to the Active state.
If you want to automatically trigger a failover from the active to the standby NameNode, when the active node has failed, you can configure automatic failover.
Default implementation provided with Hadoop framework uses ZooKeeper for automatic failover. There is a ZooKeeper client ZKFailoverController (ZKFC) which also monitors and manages the state of the NameNode.
Each of the machines which runs a NameNode also runs a ZKFC. The ZKFC monitors the health of its local Namenode and marks its healthy or unhealthy based on that.
When the local NameNode is healthy, the ZKFC holds a session open in ZooKeeper. If the local NameNode is active, it also holds a special "lock" znode. If the session expires (When the Namenode is marked unhealthy), the lock node will be automatically deleted.
If ZKFC sees that lock znode is not held by any node it will itself try to acquire the lock. If it succeeds, it is responsible for running a failover to make its local NameNode active. In the fail over process, first the previous active is fenced if necessary, and then the local NameNode transitions to active state.
Fencing method in HDFS HA
In a highly available cluster only one of the Namenode should be active at a time for the correct operation of the cluster. Otherwise both namenodes will become active and try to process client requests resulting in corruption of data and data loss.
As Example- Because of slow network the active Namenode fails the healthcheck and failover transition starts even if the previously active Namenode is still active.
In case of failover if it can't be verified that the previous Active node has relinquished its Active state, the fencing process is responsible for cutting off the previously active Namenode’s access to the shared edits storage. This prevents it from making any further edits to the namespace.
HA with Quorum Journal Manager allows only one NameNode to write to the JournalNodes, so there is no potential for corrupting the file system metadata. However, when a failover occurs, it is still possible that the previous Active NameNode could serve read requests to clients, which may be out of date.
Configuring HA Cluster
In HDFS high availability cluster in order to configure HA NameNodes, you need to add several configuration options to your hdfs-site.xml configuration file.
dfs.nameservices- Choose a logical name for this nameservice, for example "mycluster"
<property> <name>dfs.nameservices</name> <value>mycluster</value> </property>
dfs.ha.namenodes.[nameservice ID]- To provide unique identifiers for each NameNode in the nameservice. For example, if you used “mycluster” as the nameservice ID previously, and you wanted to use “nn1” and “nn2” as the individual IDs of the NameNodes.
<property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property>
Then you need to use the fully qualified name for other configuration. As example if you have to configure the HTTP address for each Namenode to listen on.
<property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>machine1.example.com:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>machine2.example.com:50070</value> </property>
For fencing, there are two methods which ship with Hadoop: shell and sshfence.
sshfence- SSH to the Active NameNode and kill the process.
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property>
shell- Run an arbitrary shell command to fence the Active NameNode
The shell fencing method runs an arbitrary shell command. It may be configured like so:
<property> <name>dfs.ha.fencing.methods</name> <value>shell(/path/to/my/script.sh arg1 arg2 ...)</value> </property>
That's all for the topic HDFS High Availability. If something is missing or you have something to share about the topic please write a comment.
You may also like
No comments:
Post a Comment