As per the replica placement policy in Hadoop each HDFS block is replicated across different nodes. Default replication factor is 3 which means by default each HDFS block is replicated on three different nodes in order to make HDFS reliable and fault tolerant.
Considerations for HDFS replica placement policy
When blocks are replicated following points are to be considered-
- Large HDFS instances run on a cluster of computers that commonly spread across many racks. Communication between two nodes in different racks has to go through switches.
- In most cases, network bandwidth between machines in the same rack is greater than network bandwidth between machines in different racks.
- Placing all the replicas on the same node (where client is) will provide the fastest access but it will be of little use as all the replicas will be lost in case of node failure.
HDFS replica placement strategy
Taking the above points in consideration where-
- Off-rack communication has to go through switches means more time is spent.
- Keeping block replica where client is, means fastest access.
Hadoop framework uses the rake aware replica placement policy where all these points are given importance.
For the default case where the replication factor is three, Hadoop’s replica placement policy is as follows-
- Put one replica on the node where client is. If client is not in the cluster then the node is chosen randomly.
- Another replica is placed on a node in a different (remote) rack.
- Third replica is also placed in the same rack as second but the node is different, chosen at random.
If the replication factor is greater than 3, the placement of the 4th and following replicas are determined randomly while keeping the number of replicas per rack below the upper limit (which is basically (replicas - 1) / racks + 2).
For replication factor of 3, HDFS replica placement might look like the given figure.
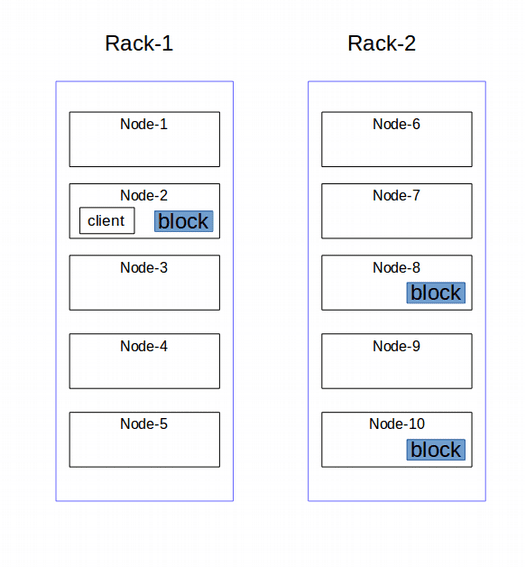
For replicating the blocks to Datanodes HDFS uses pipelining. Once the client gets the list of Datanodes from the Namenode, client streams the block data to the first Datanode, that Datanode copies the data to the next Datanode and so on to get the configured replication factor.
That's all for the topic HDFS Replica Placement Policy. If something is missing or you have something to share about the topic please write a comment.
You may also like
- Java Program to Write a File in HDFS
- Capacity Scheduler in Yarn
- OutputCommitter in Hadoop MapReduce
- Java Program to Find First Non-Repeated Character in The Given String
- Java try-with-resources With Examples
- Java Immutable Set With Examples
- Why String is Immutable in Java
- Injecting List, Set or Map in Spring
No comments:
Post a Comment