In this post we’ll see what all happens internally with in the Hadoop framework to execute a job when a MapReduce job is submitted to YARN.
The three main components when running a MapReduce job in YARN are-
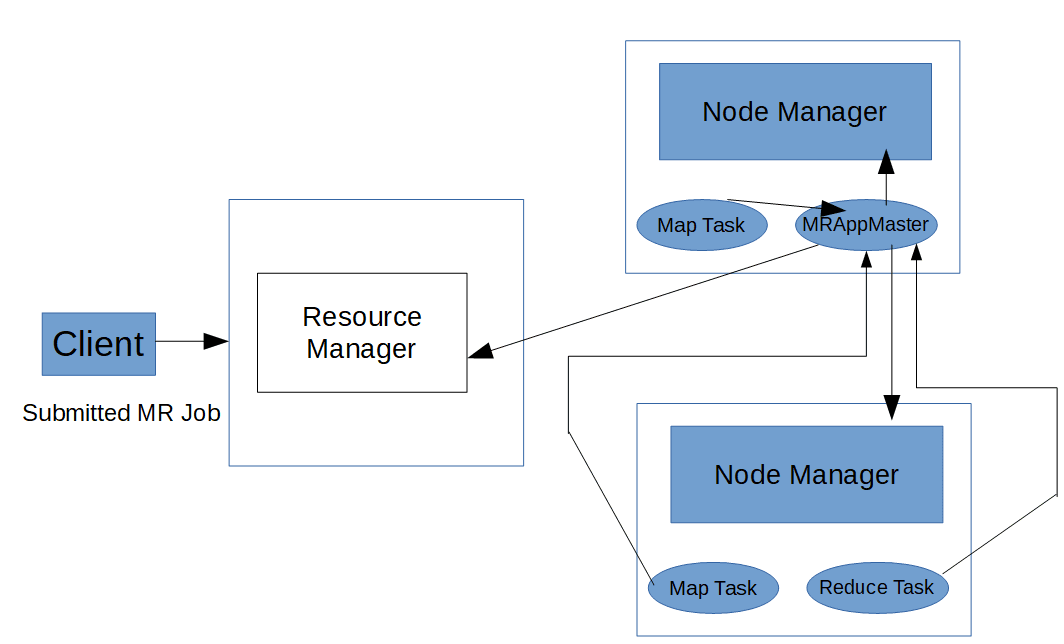
- The client which submits a job.
- YARN daemons that manage the resources and report task progress, these daemons are ResourceManager, NodeManager and ApplicationMaster.
- MapReduce tasks that run on the containers allocated by YARN.
Steps for running a MapReduce job in YARN are as follows-
- Submit the application. This is handled by Job and YARNClient.
- ResourceManager through its scheduler allocates a container for the submitted job.
- Application specific ApplicationMaster, which in case of MapReduce application is MRAppMaster starts running on that container.
- MRAppMaster negotiates containers from ResourceManager based on the Map and Reduce tasks requirements.
- Once the containers are allocated by ResourceManager, MRAppMaster communicates with NodeManagers of the nodes where containers are allocated to launch those containers. NodeManager also manage the resources for the containers.
- The MRAppMaster executes the Mapper/Reducer task as a child process in those containers.
- Once all the tasks are finished the ApplicationMaster releases the containers and shuts down.
Submitting the job
Job is the primary interface by which user-job interacts with the ResourceManager.
The job submission process involves:
- Checking the input and output specifications of the job. Which involves checking if input and output paths are given correctly or not.
- Computing the InputSplit values for the job.
- Setting up the requisite accounting information for the DistributedCache of the job, if necessary.
- Copying the job’s jar and configuration to the MapReduce system directory on the FileSystem.
- Submitting the job to the ResourceManager. This can be done through setting up a
YarnClientobject.If you run a MapReduce job you can see line similar to this on your console- impl.YarnClientImpl: Submitted application application_1520505776000_0002
For submitting the job any of the following two methods can be used-
- Job.submit(): Submit the job to the cluster and return immediately.
- Job.waitForCompletion(boolean) : Submit the job to the cluster and wait for it to finish.
Starting ApplicationMaster
Once YARN ResourceManager receives the request for application submission, it will initially allocate a single
container to the application through YARN scheduler. This container is used by ResourceManager to
launch the application specific ApplicationMaster. For MapReduce applications this ApplicationMaster is
MRAppMaster.
It is the job of ApplicationMaster to communicate with ResourceManager for further resources and to handle application execution.
Executing Application
ApplicationMaster retrieves the input splits which were already computed by the YARNClient.
Here note that the Hadoop MapReduce framework spawns one map task for each InputSplit generated by the InputFormat for the job. The number of reduce task is determined by the mapreduce.job.reduces property (in mapred-site.xml) which sets the default number of reduce tasks per job.
Once ApplicatioMaster knows how many map and reduce tasks have to be spawned, it negotiates with ResourceManager to get resource containers to run those tasks.Properties used for determining memory and CPU requirements for the map and reduce tasks are in mapred-site.xml.
- mapreduce.map.memory.mb- The amount of memory to request from the scheduler for each map task. Default value is 1024 MB.
- mapreduce.map.cpu.vcores- The number of virtual cores to request from the scheduler for each map task. Default value is 1.
- mapreduce.reduce.memory.mb- The amount of memory to request from the scheduler for each reduce task. Default value is 1024 MB.
- mapreduce.reduce.cpu.vcores- The number of virtual cores to request from the scheduler for each reduce task. Default value is 1.
ResourceManager will send information about the containers where map and reduce tasks can be started. These containers may be any node on the cluster though for Map tasks scheduler will try to get container on the same node where the input split is to make the map task data local.
ApplicationMaster (MRAppMaster) communicate with the NodeManagers of the nodes where the allocated
containers reside to launch those containers. The MRAppMaster executes the Mapper/Reducer task in the launched containers
as a child process in a separate jvm.
Task updates
The running map and reduce tasks provides information about the task progress and current status to the ApplicationMaster.
Client that submitted the job also receives the current status from the ApplicationMaster.
ApplicationMaster also sends periodic heart beats to the ResourceManager.
Task Completion
When all the map and reduce tasks for the submitted jobs are completed, ApplicationMaster can change the status for the job to "Successful". ApplicationMaster also exists when the job is complete.
That's all for the topic MapReduce Execution Internal Steps in YARN. If something is missing or you have something to share about the topic please write a comment.
You may also like
- Counters in Hadoop MapReduce
- How to Chain MapReduce Job in Hadoop
- Java Program to Compress File in bzip2 Format in Hadoop
- Uber Task in YARN
- Java Pass by Value or Pass by Reference
- How to Convert String to int in Java
- Java Exception Handling Interview Questions And Answers
- Spring Data JPA Pagination and Sorting Example
- isinstance() in Python With Examples
No comments:
Post a Comment